For each
Last modified on 10-Jul-24
Use a for each configuration to execute checks against multiple datasets during a scan.
for each dataset T:
datasets:
- dim_products%
- fact%
- exclude fact_survey_response
checks:
- row_count > 0
✖️ Requires Soda Core Scientific (included in a Soda Agent)
✔️ Supported in Soda Core
✔️ Supported in Soda Library + Soda Cloud
✔️ Supported in Soda Cloud Agreements + Soda Agent
✖️ Available as a no-code check
Define a for each configuration
Limitations and specifics
Optional check configurations
Add a dynamic name to for each checks
For each results in Soda Cloud
Go further
Define a for each configuration
Add a for each section to your checks configuration to specify a list of checks you wish to execute on multiple datasets.
- Add a
for each dataset Tsection header anywhere in your YAML file. The purpose of theTis only to ensure that everyfor eachconfiguration has a unique name. - Nested under the section header, add two nested keys, one for
datasetsand one forchecks. - Nested under
datasets, add a list of datasets against which to run the checks. Refer to the example below that illustrates how to useincludeandexcludeconfigurations and wildcard characters (%) . - Nested under
checks, write the checks you wish to execute against all the datasets listed underdatasets.
for each dataset T:
datasets:
# include the dataset
- dim_customers
# include all datasets matching the wildcard expression
- dim_products%
# (optional) explicitly add the word include to make the list more readable
- include dim_employee
# exclude a specific dataset
- exclude fact_survey_response
# exclude any datasets matching the wildcard expression
- exclude prospective_%
checks:
- row_count > 0
Limitations and specifics for for each
- For each is not compatible with dataset filters.
- Soda dataset names matching is case insensitive.
- You cannot use quotes around dataset names in a for each configuration.
- If any of your checks specify column names as arguments, make sure the column exists in all datasets listed under the
datasetsheading. - To add multiple for each configurations, configure another
for eachsection header with a different letter identifier, such asfor each dataset R.
Optional check configurations
| Supported | Configuration | Documentation |
|---|---|---|
| ✓ | Define a name for a for each check; see example. | Customize check names |
| ✓ | Add an identity to a check. | Add a check identity |
| ✓ | Define alert configurations to specify warn and fail alert conditions; see example. | Add alert configurations. |
| ✓ | Apply an in-check filter to return results for a specific portion of the data in your dataset; see example. | Add an in-check filter. |
| Use quotes when identifying dataset or column names. | - | |
| ✓ | Use wildcard characters ( % ) in values in the for each configuration; see example. | - |
| Apply a dataset filter to partition data during a scan. | - |
Example with check name
for each dataset T:
datasets:
- dim_employee
checks:
- max(vacation_hours) < 80:
name: Too many vacation hours for US Sales
Example with alert configuration
for each dataset T:
datasets:
- dim_employee
- dim_customer
checks:
- row_count:
fail:
when < 5
warn:
when > 10
Example with in-check filter
for each dataset T:
datasets:
- dim_employee
checks:
- max(vacation_hours) < 80:
filter: sales_territory_key = 11
Example with wildcard
for each dataset T:
datasets:
- dim_%
checks:
- row_count > 1
Add a dynamic name to for each checks
To keep your for each check results organized in Soda Cloud, you may wish to dynamically add a name to each check so that you can easily identify to which dataset the check result applies.
For example, if you use for each to execute an anomaly detection check on many datasets, you can use a variable in the syntax of the check name so that Soda dynamically adds a dataset name to each check result.
for each dataset R:
datasets:
- retail%
checks:
- anomaly detection for row_count:
name: Row count anomaly for ${R}
For each results in Soda Cloud
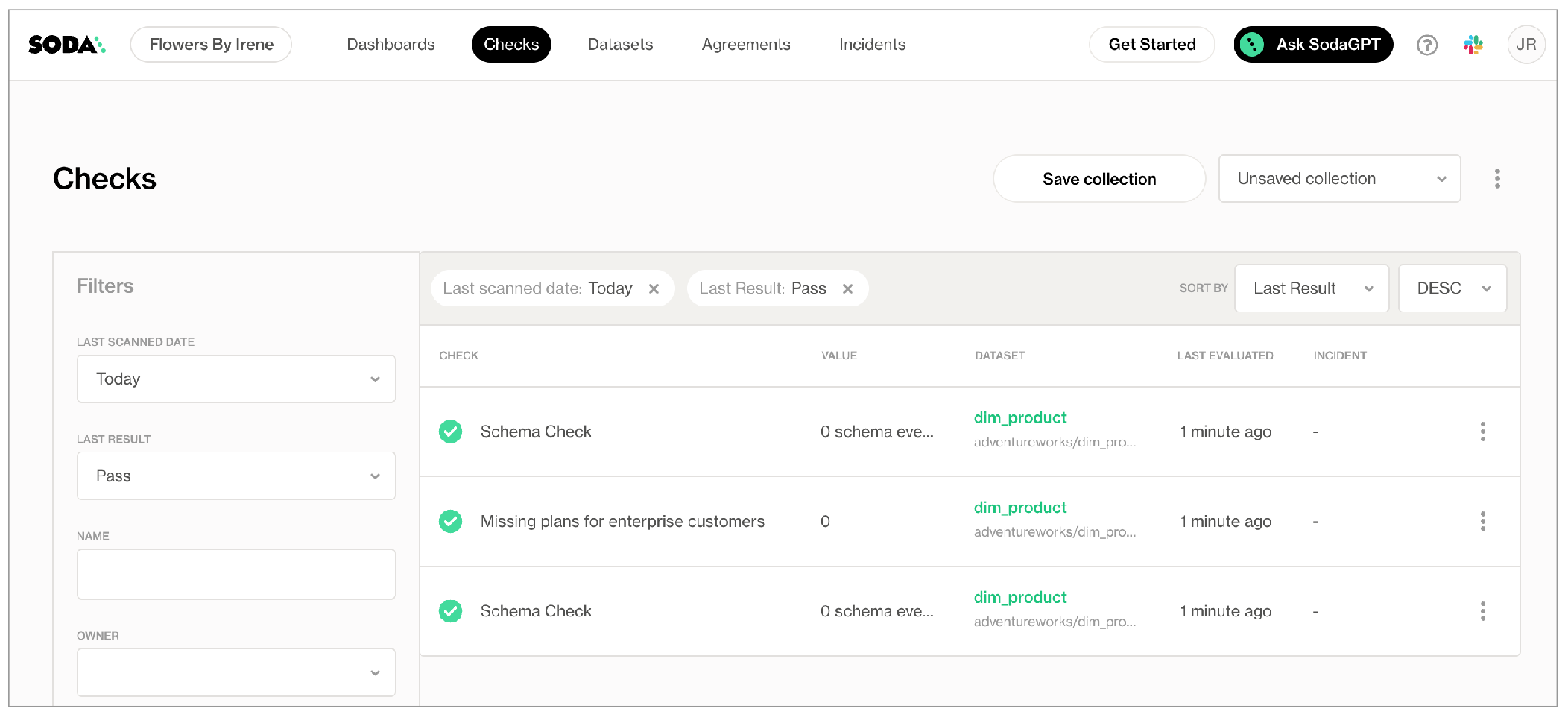
Soda pushes the check results for each dataset to Soda Cloud where each check appears in the Checks dashboard, with an icon indicating their latest scan result. Filter the results by dataset to review dataset-specific results.
for each dataset T:
datasets:
- dim_employee
- dim_customer
checks:
- row_count > 1
Go further
- Need help? Join the Soda community on Slack.
- Reference tips and best practices for SodaCL.
Was this documentation helpful?
What could we do to improve this page?
- Suggest a docs change in GitHub.
- Share feedback in the Soda community on Slack.
Documentation always applies to the latest version of Soda products
Last modified on 10-Jul-24